LFCS: Monitorizați utilizarea resurselor proceselor Linux și setați limite de proces pe bază de utilizator - Partea 14
Datorită modificărilor recente ale obiectivelor examenului de certificare LFCS în vigoare începând cu 2 februarie 2016, adăugăm articolele necesare la seria LFCS publicată aici. Pentru a vă pregăti pentru acest examen, sunteți încurajat să treceți și prin seria LFCE.

Fiecare administrator de sistem Linux trebuie să știe cum să verifice integritatea și disponibilitatea hardware-ului, resurselor și proceselor cheie. În plus, stabilirea limitelor de resurse pe bază de utilizator trebuie, de asemenea, să facă parte din setul de abilități ale acestuia.
În acest articol vom explora câteva modalități de a ne asigura că sistemul atât hardware-ul, cât și software-ul se comportă corect, pentru a evita potențialele probleme care pot cauza opriri neașteptate ale producției și pierderi de bani.
Statistici procesoare de raportare Linux
Cu mpstat puteți vizualiza activitățile pentru fiecare procesor în mod individual sau pentru sistemul ca întreg, atât ca un instantaneu unic, cât și dinamic.
Pentru a utiliza acest instrument, va trebui să instalați sysstat:
yum update && yum install sysstat [On CentOS based systems]
aptitutde update && aptitude install sysstat [On Ubuntu based systems]
zypper update && zypper install sysstat [On openSUSE systems]
Citiți mai multe despre sysstat și despre utilitățile sale la Aflați Sysstat și utilitatile sale mpstat, pidstat, iostat și sar în Linux
După ce ați instalat mpstat, utilizați-l pentru a genera rapoarte cu statisticile procesoarelor.
Pentru a afișa 3 rapoarte globale de utilizare a CPU (-u) pentru toate procesoarele (după cum este indicat de -P ALL) la un interval de 2 secunde , face:
mpstat -P ALL -u 2 3
Ieșire eșantion
Linux 3.19.0-32-generic (linux-console.net) Wednesday 30 March 2016 _x86_64_ (4 CPU)
11:41:07 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:09 IST all 5.85 0.00 1.12 0.12 0.00 0.00 0.00 0.00 0.00 92.91
11:41:09 IST 0 4.48 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 94.53
11:41:09 IST 1 2.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 97.00
11:41:09 IST 2 6.44 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 92.57
11:41:09 IST 3 10.45 0.00 1.99 0.00 0.00 0.00 0.00 0.00 0.00 87.56
11:41:09 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:11 IST all 11.60 0.12 1.12 0.50 0.00 0.00 0.00 0.00 0.00 86.66
11:41:11 IST 0 10.50 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 88.50
11:41:11 IST 1 14.36 0.00 1.49 2.48 0.00 0.00 0.00 0.00 0.00 81.68
11:41:11 IST 2 2.00 0.50 1.00 0.00 0.00 0.00 0.00 0.00 0.00 96.50
11:41:11 IST 3 19.40 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 79.60
11:41:11 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:41:13 IST all 5.69 0.00 1.24 0.00 0.00 0.00 0.00 0.00 0.00 93.07
11:41:13 IST 0 2.97 0.00 1.49 0.00 0.00 0.00 0.00 0.00 0.00 95.54
11:41:13 IST 1 10.78 0.00 1.47 0.00 0.00 0.00 0.00 0.00 0.00 87.75
11:41:13 IST 2 2.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00 97.00
11:41:13 IST 3 6.93 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 92.57
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 7.71 0.04 1.16 0.21 0.00 0.00 0.00 0.00 0.00 90.89
Average: 0 5.97 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 92.87
Average: 1 9.24 0.00 1.16 0.83 0.00 0.00 0.00 0.00 0.00 88.78
Average: 2 3.49 0.17 1.00 0.00 0.00 0.00 0.00 0.00 0.00 95.35
Average: 3 12.25 0.00 1.16 0.00 0.00 0.00 0.00 0.00 0.00 86.59
Pentru a vedea aceleași statistici pentru un anumit CPU (CPU 0 în următorul exemplu), utilizați:
mpstat -P 0 -u 2 3
Ieșire eșantion
Linux 3.19.0-32-generic (linux-console.net) Wednesday 30 March 2016 _x86_64_ (4 CPU)
11:42:08 IST CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
11:42:10 IST 0 3.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 0.00 96.50
11:42:12 IST 0 4.08 0.00 0.00 2.55 0.00 0.00 0.00 0.00 0.00 93.37
11:42:14 IST 0 9.74 0.00 0.51 0.00 0.00 0.00 0.00 0.00 0.00 89.74
Average: 0 5.58 0.00 0.34 0.85 0.00 0.00 0.00 0.00 0.00 93.23
Ieșirea comenzilor de mai sus arată aceste coloane:
CPU: numărul procesorului ca număr întreg sau cuvântul all ca medie pentru toate procesoarele.%usr: procentul de utilizare a procesorului în timp ce rulează aplicații la nivel de utilizator.%nice: La fel ca%usr, dar cu o prioritate bună.%sys: procentul de utilizare a procesorului care a avut loc în timpul executării aplicațiilor kernel. Aceasta nu include timpul petrecut cu întreruperile sau gestionarea hardware-ului.%iowait: Procentul de timp în care CPU-ul dat (sau tot) a fost inactiv, timp în care a fost programată o operațiune I/O care consumă mult resurse pe acel CPU. O explicație mai detaliată (cu exemple) poate fi găsită aici.%irq: procentul de timp petrecut cu întreruperile hardware.%soft: La fel ca%irq, dar cu întreruperi software.%steal: procentul de timp petrecut în așteptare involuntară (timp furat sau furat) atunci când o mașină virtuală, ca oaspete, „câștigă” atenția hipervizorului în timp ce concurează pentru CPU(e). Această valoare trebuie menținută cât mai mică posibil. O valoare ridicată în acest domeniu înseamnă că mașina virtuală se blochează – sau va fi în curând.%guest: procentul de timp petrecut rulând un procesor virtual.%idle: procentul de timp în care CPU-urile nu executau nicio sarcină. Dacă observați o valoare scăzută în această coloană, acesta este un indiciu că sistemul este plasat sub o sarcină mare. În acest caz, va trebui să aruncați o privire mai atentă la lista de procese, așa cum vom discuta într-un minut, pentru a determina ce cauzează.
Pentru a pune procesorul sub o sarcină oarecum mare, executați următoarele comenzi și apoi executați mpstat (după cum este indicat) într-un terminal separat:
dd if=/dev/zero of=test.iso bs=1G count=1
mpstat -u -P 0 2 3
ping -f localhost # Interrupt with Ctrl + C after mpstat below completes
mpstat -u -P 0 2 3
În cele din urmă, comparați cu rezultatul mpstat în circumstanțe „normale”:

După cum puteți vedea în imaginea de mai sus, CPU 0 a fost supus unei sarcini grele în timpul primelor două exemple, așa cum este indicat de coloana %idle.
În secțiunea următoare vom discuta despre cum să identificăm aceste procese care necesită resurse, cum să obținem mai multe informații despre ele și cum să luăm măsurile adecvate.
Raportarea proceselor Linux
Pentru a enumera procesele, sortându-le după utilizarea CPU, vom folosi binecunoscuta comandă ps cu -eo (pentru a selecta toate procesele cu format definit de utilizator) și --sort (pentru a specifica o ordine de sortare personalizată), astfel:
ps -eo pid,ppid,cmd,%cpu,%mem --sort=-%cpu
Comanda de mai sus va afișa numai PID, PPID, comanda asociată procesului și procentul de utilizare a CPU și RAM sortat după procentul de utilizare a procesorului în ordine descrescătoare . Când este executat în timpul creării fișierului .iso, iată primele câteva rânduri ale rezultatului:
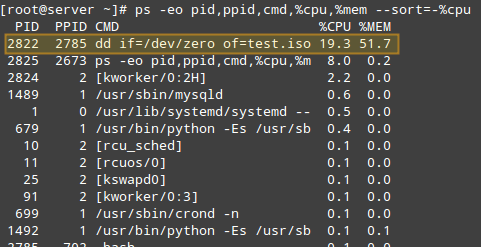
Odată ce am identificat un proces de interes (cum ar fi cel cu PID=2822), putem naviga la /proc/PID (/proc/2822 în acest caz) și faceți o listare a directorului.
Acest director este locul în care sunt păstrate mai multe fișiere și subdirectoare cu informații detaliate despre acest proces anume în timp ce rulează.
De exemplu:
/proc/2822/ioconține statistici IO pentru proces (numărul de caractere și octeți citiți și scriere, printre altele, în timpul operațiunilor IO)./proc/2822/attr/currentarată atributele de securitate SELinux curente ale procesului./proc/2822/cgroupdescrie grupurile de control (cgroups pe scurt) cărora le aparține procesul dacă este activată opțiunea de configurare a nucleului CONFIG_CGROUPS, pe care o puteți verifica cu:
cat /boot/config-$(uname -r) | grep -i cgroups
Dacă opțiunea este activată, ar trebui să vedeți:
CONFIG_CGROUPS=y
Folosind cgroups, puteți gestiona cantitatea de utilizare permisă a resurselor pe o bază de proces, așa cum este explicat în capitolele 1 până la 4 din ghidul de gestionare a resurselor Red Hat Enterprise Linux 7, în capitolul 9 din Analiza sistemului openSUSE și ghid de reglare și în secțiunea Grupuri de control din documentația Ubuntu 14.04 Server.
/proc/2822/fd este un director care conține o legătură simbolică pentru fiecare descriptor de fișier pe care procesul l-a deschis. Următoarea imagine arată aceste informații pentru procesul care a fost pornit în tty1 (primul terminal) pentru a crea imaginea .iso:
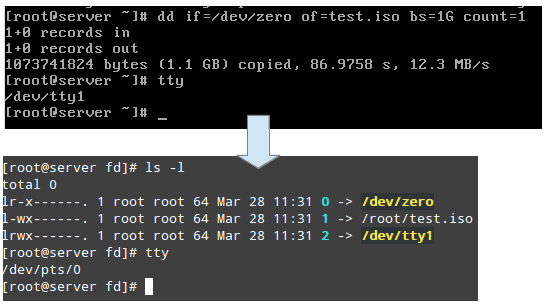
Imaginea de mai sus arată că stdin (descriptor de fișier 0), stdout (descriptor de fișier 1) și stderr (descriptor de fișier 2) sunt mapate la /dev/zero, /root/test.iso și .
Mai multe informații despre /proc pot fi găsite în documentul „Sistemul de fișiere /proc ” păstrat și întreținut de Kernel.org și în Manualul programatorului Linux.
Stabilirea limitelor de resurse pe bază de utilizator în Linux
Dacă nu sunteți atent și permiteți oricărui utilizator să ruleze un număr nelimitat de procese, este posibil să aveți în cele din urmă o închidere neașteptată a sistemului sau să fiți blocat pe măsură ce sistemul intră într-o stare inutilizabilă. Pentru a preveni acest lucru, ar trebui să stabiliți o limită a numărului de procese pe care utilizatorii le pot începe.
Pentru a face acest lucru, editați /etc/security/limits.conf și adăugați următoarea linie în partea de jos a fișierului pentru a seta limita:
* hard nproc 10
Primul câmp poate fi folosit pentru a indica fie un utilizator, un grup sau toate (*), în timp ce al doilea câmp impune o limită strictă a numărului de procese (nproc) la 10. Pentru a aplica modificările, este suficientă deconectarea și reconectarea.
Astfel, să vedem ce se întâmplă dacă un anumit utilizator, altul decât root (fie unul legitim sau nu) încearcă să pornească o bombă shell fork. Dacă nu am fi implementat limite, aceasta ar lansa inițial două instanțe ale unei funcții și apoi ar duplica fiecare dintre ele într-o buclă fără sfârșit. Astfel, ar duce în cele din urmă sistemul dvs. la un crawl.
Cu toate acestea, cu restricția de mai sus în vigoare, bomba cu furcă nu reușește, dar utilizatorul va fi în continuare blocat până când administratorul de sistem oprește procesul asociat cu aceasta:

SFAT: Alte posibile restricții posibile de ulimit sunt documentate în fișierul limits.conf.
Linux Alte instrumente de gestionare a proceselor
Pe lângă instrumentele discutate anterior, un administrator de sistem poate avea nevoie și de:
a) Modificați prioritatea de execuție (utilizarea resurselor de sistem) a unui proces utilizând renice. Aceasta înseamnă că nucleul va aloca procesului mai multe sau mai puține resurse de sistem în funcție de prioritatea atribuită (un număr cunoscut în mod obișnuit ca „frumusețe ” într-un interval de la -20 la 19).
Cu cât valoarea este mai mică, cu atât este mai mare prioritatea de execuție. Utilizatorii obișnuiți (alții decât root) pot modifica doar frumusețea proceselor pe care le dețin la o valoare mai mare (adică o prioritate de execuție mai mică), în timp ce root poate modifica această valoare pentru orice proces și o poate crește sau micșora.
Sintaxa de bază a lui renice este următoarea:
renice [-n] <new priority> <UID, GID, PGID, or empty> identifier
Dacă argumentul după noua valoare de prioritate nu este prezent (gol), acesta este setat la PID în mod implicit. În acest caz, calitatea procesului cu PID=identifier este setată la
b) Întrerupeți execuția normală a unui proces atunci când este necesar. Acest lucru este cunoscut sub denumirea de „ucidere” a procesului. Sub capotă, aceasta înseamnă trimiterea unui semnal procesului pentru a-și termina corect execuția și a elibera orice resurse utilizate într-o manieră ordonată.
Pentru a opri un proces, utilizați comanda kill după cum urmează:
kill PID
Alternativ, puteți utiliza pkill pentru a încheia toate procesele unui proprietar dat (-u) sau unui proprietar de grup (-G) sau chiar acele procese care au un PPID în comun (-P). Aceste opțiuni pot fi urmate de reprezentarea numerică sau de numele real ca identificator:
pkill [options] identifier
De exemplu,
pkill -G 1000
va distruge toate procesele deținute de grupul cu GID=1000.
Și,
pkill -P 4993
va ucide toate procesele al căror PPID este 4993.
Înainte de a rula un pkill, este o idee bună să testați mai întâi rezultatele cu pgrep, poate folosind și opțiunea -l pentru a lista numele proceselor. Este nevoie de aceleași opțiuni, dar returnează doar PID-urile proceselor (fără a lua nicio acțiune suplimentară) care ar fi oprite dacă este folosit pkill.
pgrep -l -u gacanepa
Acest lucru este ilustrat în imaginea următoare:

rezumat
În acest articol, am explorat câteva modalități de a monitoriza utilizarea resurselor pentru a verifica integritatea și disponibilitatea componentelor hardware și software critice într-un sistem Linux.
De asemenea, am învățat cum să luăm măsurile adecvate (fie prin ajustarea priorității de execuție a unui anumit proces, fie prin încheierea acestuia) în circumstanțe neobișnuite.
Sperăm că conceptele explicate în acest tutorial au fost utile. Dacă aveți întrebări sau comentarii, nu ezitați să ne contactați folosind formularul de contact de mai jos.